Day 72: Adaptive Batching - Self-Tuning Performance Optimization
Day 72: Adaptive Batching - Self-Tuning Performance Optimization
What We're Building Today
Today we're implementing an intelligent system that automatically optimizes performance without any manual tuning. Think of it as cruise control for your log processing system - it constantly adjusts to maintain peak efficiency.
High-Level Agenda:
End Goal: A system that improves throughput by 30-70% while keeping your servers healthy.
The Performance Paradox
Here's what most engineers get wrong about batching: bigger isn't always better. Small batches provide low latency but waste CPU cycles on overhead. Large batches maximize throughput but can overwhelm memory and cause processing delays.
The sweet spot constantly shifts based on:
Netflix's recommendation engine processes millions of user interactions using adaptive batching. During peak hours, batches grow to handle volume. During quiet periods, they shrink for responsiveness. This automatic tuning prevents both resource waste and performance degradation.
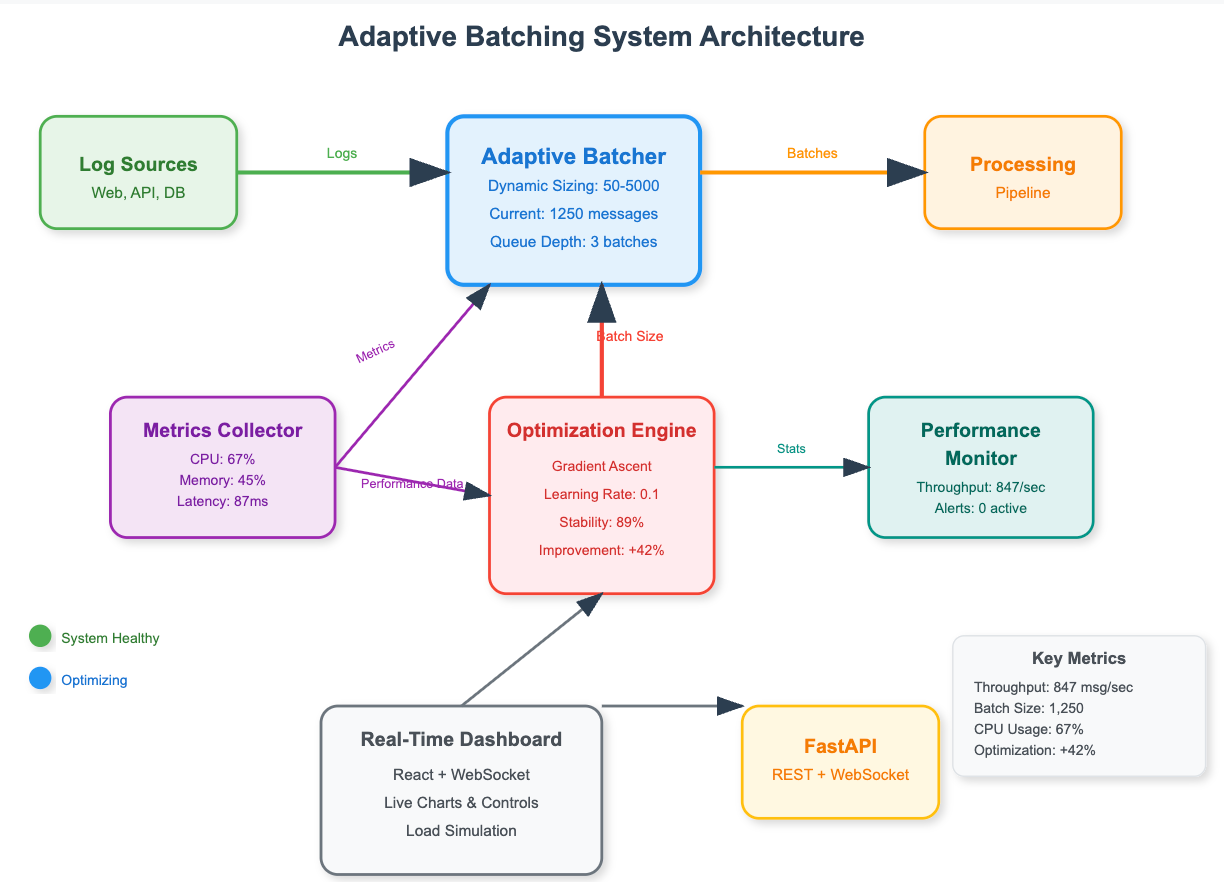
Core Concept: The Adaptive Feedback Loop
[

](https://substackcdn.com/image/fetch/\)s!UH6p!,fauto,qauto:good,flprogressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd4a5e295-acae-4398-be40-cbdb4ecbb323_1224x882.png)
\[ COMPONENT ARCHITECTURE DIAGRAM\]
Adaptive batching implements a control feedback loop:
1. Monitor: Collect real-time performance metrics
2. Analyze: Calculate optimal batch size using performance models
3. Adjust: Modify batch parameters gradually to avoid oscillation
4. Measure: Track throughput and latency changes
5. Repeat: Continuously optimize based on new conditions
[Read more](https://sdcourse.substack.com/p/day-72-adaptive-batching-self-tuning)
Write a comment