Notes on pretraining parallelisms and failed training runs.
Deeply researched interviews
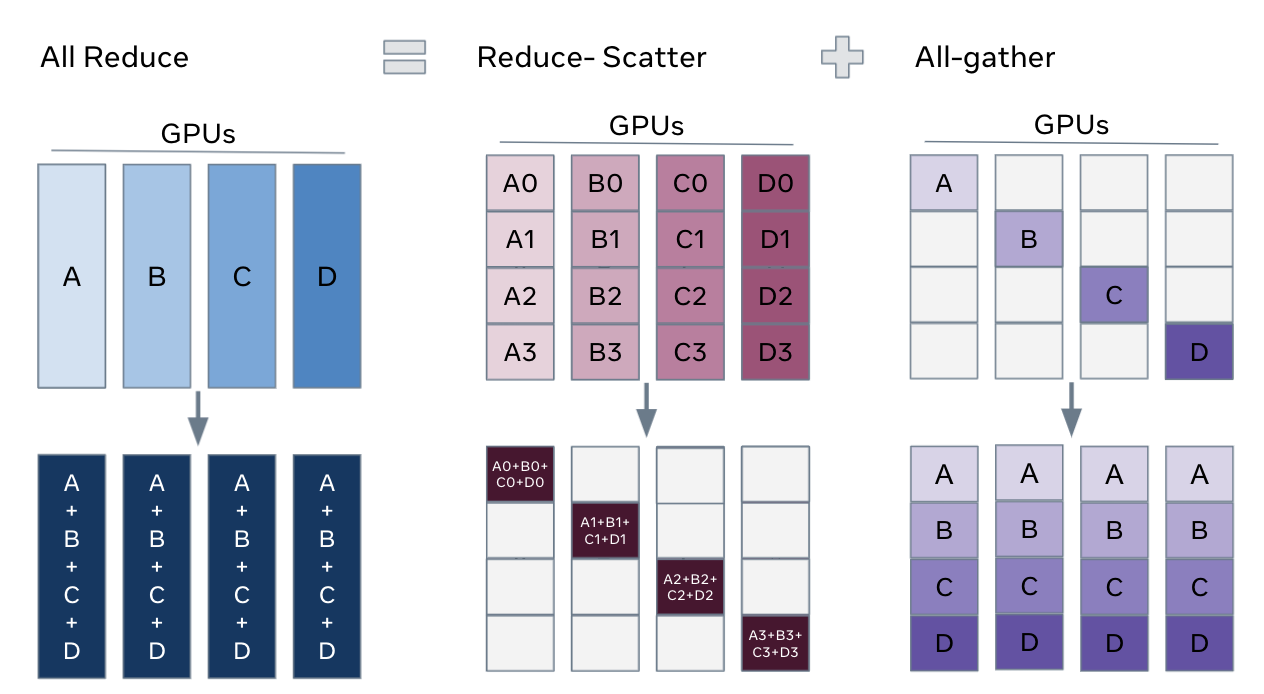
Notes on pretraining parallelisms and failed training runs. AI pretraining runs can fail due to issues like breaking causality with expert routing or token dropping, and introducing bias through numerical precision bugs such as using FP16 for collectives. Scaling these models requires complex parallelism strategies like Fully Sharded Data Parallel (FSDP) and Pipeline Parallelism, each with its own set of challenges and trade-offs that can lead to performance bottlenecks or architectural constraints.
- Pretraining runs fail due to breaking causality (e.g., expert routing, token dropping) and introducing bias (e.g., FP16 numerical precision bugs).
- Expert routing in training can break causality by allocating tokens based on future dependencies, unlike inference.
- FP16’s limited granularity can cause significant numerical errors when summing many small values, as seen in an early GPT-4 training issue.
- Fully Sharded Data Parallel (FSDP) is a default parallelism strategy, offering a good balance of communication and computation, but can be limited by communication crossover points.
- Pipeline Parallelism is introduced when FSDP scales poorly, but it suffers from bubbles (underutilized GPUs) and architectural constraints that hinder research.
- Optimizing communication in large-scale training involves techniques like hierarchical collectives to minimize bottlenecks.
- The complexity of AI training suggests that new issues will continue to emerge at larger scales, making fully automated kernel writing a distant goal. Continue reading https://foxvector.com/articles/b8a54cd9-b855-467b-a54c-c157a74802ef
No comments yet.
Write a comment